
Las consultas de base de datos lentas drenan silenciosamente el rendimiento de tu aplicación, frustrando a los usuarios e inflando los costos de infraestructura. Estas cinco técnicas probadas te ayudarán a eliminar los cuellos de botella de latencia y entregar la experiencia rápida y receptiva que tus usuarios esperan.
Un enfoque que simplifica la optimización de bases de datos es construir con Adalo, un constructor de aplicaciones sin código para aplicaciones web impulsadas por bases de datos y aplicaciones nativas de iOS y Android, una versión en las tres plataformas, publicada en la App Store de Apple y Google Play. La base de datos integrada de Adalo ofrece cero latencia de API, mientras que su infraestructura maneja el almacenamiento en caché y la optimización de consultas automáticamente, para que puedas enfocarte en tu aplicación en lugar de ajustes manuales de base de datos.
Ya sea que estés optimizando un sistema existente o lanzando un nuevo MVP, poner tu aplicación en las tiendas de aplicaciones rápidamente significa llegar a la audiencia más grande posible con notificaciones push y rendimiento nativo. Así es como hacer que tus consultas de base de datos sean ultrarrápidas.
La latencia de consultas de base de datos puede arrastrar el rendimiento de tu aplicación, frustrando a los usuarios y aumentando costos. Ya sea que estés construyendo una herramienta interna simple o una aplicación orientada al cliente con miles de usuarios, las consultas lentas crean cuellos de botella que se propagan por todo tu sistema. Así es como solucionarlo:
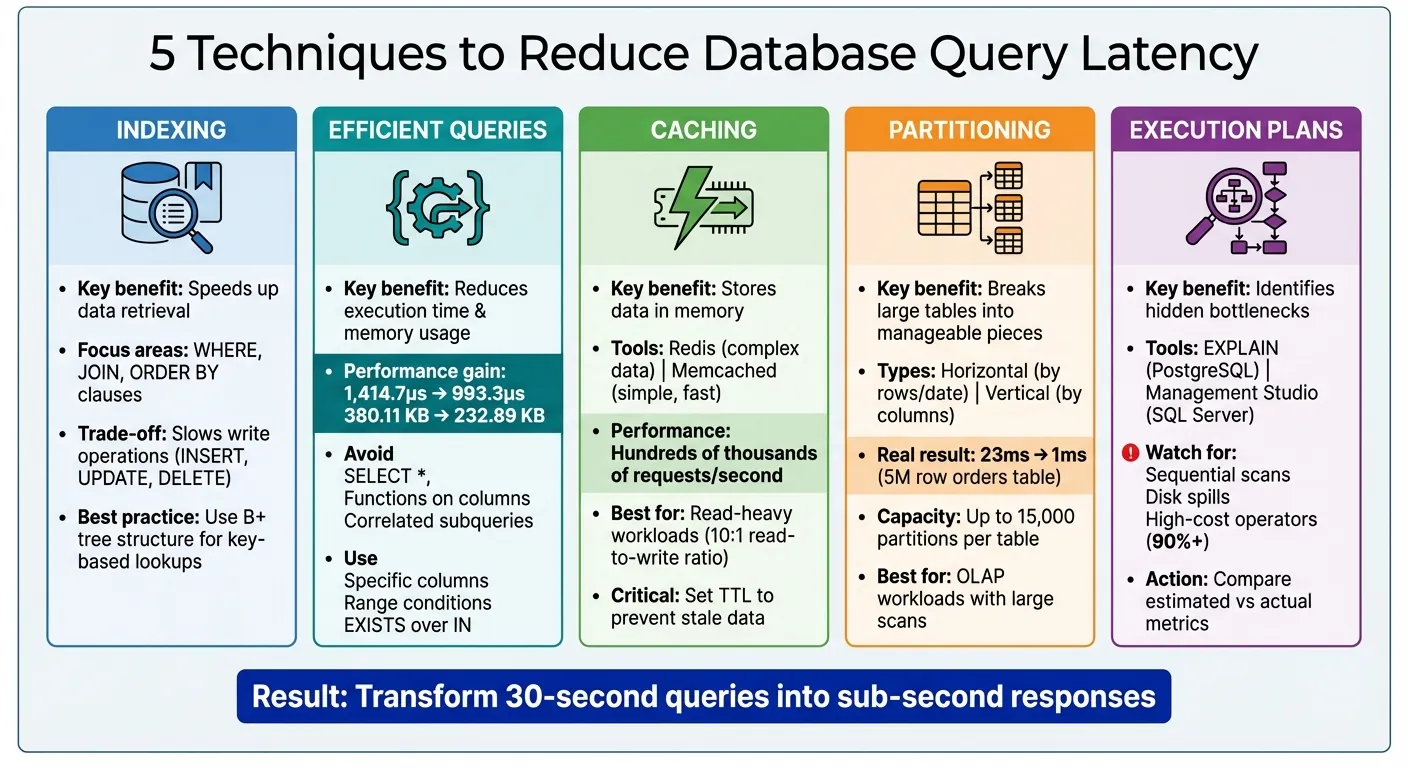
- Indexación: Usa índices para acelerar la recuperación de datos dirigiéndote a columnas en
WHERE,JOINyORDER BYcláusulas. Evita el exceso de indexación para prevenir operaciones de escritura más lentas. - Consultas eficientes: Evita
SELECT *, optimizaWHEREcondiciones para uso de índices, y minimiza uniones o subconsultas innecesarias. - Almacenamiento en caché: Almacena datos frecuentemente accedidos en memoria usando herramientas como Redis o Memcached para reducir la carga de la base de datos. Usa
TTLpara mantener los datos en caché frescos. - Particionamiento: Divide tablas grandes en partes más pequeñas o sincroniza datos entre plataformas (horizontal o vertical) para mejorar el rendimiento de consultas en conjuntos de datos masivos.
- Planes de ejecución de consultas: Analiza planes de ejecución para identificar cuellos de botella como escaneos secuenciales o derrames de disco. Ajusta índices y estructuras de consultas en consecuencia.
Optimización de latencia de consultas de base de datos: 5 técnicas clave comparadas
¿Por qué mis consultas de base de datos se ejecutan tan lentamente? - Next LVL Programming
1. Usa indexación de base de datos
Piensa en los índices de base de datos como el índice al final de un libro, actúan como atajos, apuntando directamente a las filas que necesitas en una tabla. Esto evita que el motor de la base de datos escanee cada fila, haciendo que la recuperación de datos sea mucho más rápida. La mayoría de los índices se basan en una estructura de árbol B+, que está diseñada para búsquedas rápidas basadas en claves. Configurar la indexación adecuada es un paso clave hacia la optimización de tus consultas de base de datos, especialmente al evaluar opciones de integración de bases de datos para tu aplicación.
Enfócate en indexar columnas que se usan comúnmente en WHERE, JOINy ORDER BY cláusulas, esto puede llevar a mejoras notables en el rendimiento de consultas. Por ejemplo, un índice cubierto puede obtener todas las columnas necesarias directamente, reduciendo operaciones innecesarias de entrada/salida.
Para consultas más simples, los índices de columna única a menudo hacen el trabajo. Sin embargo, para consultas con múltiples condiciones, los índices compuestos son el camino a seguir. Al crear índices compuestos, organiza las columnas estratégicamente: comienza con filtros de igualdad, sigue con filtros de rango, y luego considera la distintividad de columna.
Aunque los índices aceleran SELECT operaciones, tienen una compensación, pueden ralentizar operaciones de escritura como INSERT, UPDATEy DELETE. Para evitar gastos innecesarios, mantente atento a cómo se están usando tus índices y elimina aquellos que no añaden valor.
"Un error común de diseño es crear muchos índices especulativamente para 'dar opciones al optimizador'. El exceso de indexación resultante ralentiza las modificaciones de datos y puede causar problemas de concurrencia." - Guía de diseño de índices de Microsoft SQL Server
Mejores prácticas de indexación
Al implementar índices, considera estas directrices:
- Las claves primarias se indexan automáticamente en la mayoría de los sistemas de base de datos
- Las claves externas usadas en uniones se benefician significativamente de la indexación
- Las columnas con alta cardinalidad (muchos valores únicos) son mejores candidatos para índices que columnas con pocos valores distintos
- Audita regularmente tus índices para identificar los no utilizados que solo añaden sobrecarga de escritura
Adalo es un constructor de aplicaciones sin código para aplicaciones web impulsadas por bases de datos y aplicaciones nativas de iOS y Android, una versión en las tres plataformas, publicada en la App Store de Apple y Google Play. Los constructores de aplicaciones modernos impulsados por IA como Adalo manejan mucha de esta complejidad automáticamente. Con la revisión de infraestructura de 2026 de la plataforma, las operaciones de base de datos se ejecutan 3-4 veces más rápidas más rápido que antes, y el sistema escala la infraestructura con las necesidades de la aplicación, lo que significa que no hay límite de registros en planes pagos. Esto elimina la necesidad de optimizar manualmente los índices para la mayoría de casos de uso comunes.
2. Escribir consultas más eficientes
La forma en que estructuras una consulta puede determinar su rendimiento. Para empezar, evita usar SELECT *. En su lugar, especifica solo las columnas que realmente necesitas. Por ejemplo, si estás trabajando con un base de datos de clientes y solo necesitas el ID, nombre y correo electrónico, solicita solo esos tres campos. Extraer columnas innecesarias desperdicia memoria y ancho de banda.
La estructura de la consulta es tan importante como la indexación. Usar la búsqueda completa de entidades en ORMs (Mapeadores Objeto-Relacional) puede agregar una sobrecarga significativa. Una comparación de rendimiento reveló que cambiar a consultas sin seguimiento redujo el tiempo de ejecución de 1,414.7 microsegundos a 993.3 microsegundos y redujo el uso de memoria de 380.11 KB a 232.89 KB. Para evitar esta sobrecarga, usa proyecciones en tu ORM—métodos como .Select() en EF Core o .values() en Django—para recuperar solo los campos que necesitas.
Optimizar condiciones WHERE
Al optimizar condiciones WHERE, ten cuidado de cómo las escribes. Las funciones en columnas, como WHERE YEAR(hire_date) = 2020, impiden que los índices se utilicen de manera efectiva. En su lugar, usa condiciones basadas en rangos, como WHERE hire_date >= '2020-01-01' AND hire_date < '2021-01-01'. Este enfoque mantiene la "capacidad de búsqueda de argumentos" (SARG-ability), permitiendo que la consulta aproveche los índices. De manera similar, evita patrones con caracteres comodín al inicio en LIKE consultas, ya que fuerzan escaneos completos de tabla.
El factor principal para determinar si una consulta se ejecuta rápido o no es si utilizará adecuadamente los índices cuando sea apropiado.
– Documentación de Microsoft
Reducir uniones y subconsultas
Reduce el uso de uniones y subconsultas innecesarias. Las subconsultas correlacionadas—aquellas que dependen de la consulta externa—son particularmente problemáticas, ya que se ejecutan una vez por cada fila en el conjunto de resultados. En su lugar, reemplázalas con uniones estándar siempre que sea posible. Si estás verificando la existencia de datos, usa EXISTS en lugar de IN. El EXISTS la cláusula deja de procesar tan pronto como encuentra una coincidencia, haciéndola mucho más eficiente.
Como lo expresa Mike Payne, un experto en bases de datos: "Optimizar estas consultas es la cosa individual más impactante que puedes hacer para mejorar la velocidad y escalabilidad de tu base de datos".
Ada, el constructor de IA de Adalo, te permite describir lo que deseas y genera tu app. Magic Start crea fundaciones de aplicaciones completas a partir de una descripción, mientras que Magic Add agrega funciones mediante lenguaje natural.
Para aquellos que construyen aplicaciones sin escribir SQL directamente, la interfaz visual de Adalo abstrae estas optimizaciones. Las características asistidas por IA de la plataforma como Magic Add te permiten describir qué datos necesitas en lenguaje natural, y el sistema genera consultas eficientes automáticamente. Esto es particularmente valioso para constructores no técnicos que desean rendimiento sin profundizar en la optimización de consultas.
3. Almacenar en caché consultas frecuentes
El almacenamiento en caché es como darle a tu aplicación un impulso de memoria. En lugar de consultar la base de datos repetidamente, los datos a los que se accede frecuentemente se almacenan en memoria, reduciendo el tiempo que tarda en recuperar información. Esto evita los retrasos que vienen con el acceso a disco, que—incluso en el mejor de los casos—puede tomar decenas de milisegundos.
Dos herramientas populares para almacenamiento en caché son Redis y Memcached. Redis destaca por su capacidad para manejar estructuras de datos complejas y su opción de persistencia en disco. Por otro lado, Memcached es más simple y ligero, diseñado puramente para almacenamiento en caché de alta velocidad. Para darte una idea de su potencia, un único nodo de caché en memoria puede procesar cientos de miles de solicitudes por segundo.
Patrón cache-aside
El método de almacenamiento en caché más común es cache-aside, también llamado carga perezosa. Así es cómo funciona: la aplicación verifica el caché primero. Si los datos no están allí (un "fallo"), consulta la base de datos, recupera los datos y luego actualiza el caché. Este método es particularmente efectivo en escenarios con mucha lectura donde los datos se leen al menos 10 veces más a menudo de lo que se escriben. Al combinar esta estrategia con las técnicas de optimización de consultas anteriores, puedes reducir significativamente la carga en tu base de datos.
Para evitar que los datos obsoletos persistan, siempre establece un TTL (tiempo de vida) para tus datos en caché. Si estás trabajando con Redis, considera usar Hashes para almacenar filas de base de datos. Este enfoque te permite actualizar campos individuales sin necesidad de procesar un blob JSON completo. Además, mantén un ojo en tu proporción de aciertos de caché—una proporción baja significa que tu caché no se está utilizando de manera efectiva, lo que desperdicia memoria sin aliviar la carga de la base de datos.
"La velocidad y el rendimiento de tu base de datos pueden ser el factor más impactante para el rendimiento general de la aplicación." – AWS
Cuándo implementar almacenamiento en caché
No todas las aplicaciones necesitan una capa de almacenamiento en caché dedicada. Considera implementar almacenamiento en caché cuando:
- Las consultas de tu base de datos son consistentemente lentas a pesar de la optimización
- Múltiples usuarios solicitan los mismos datos repetidamente
- Tu aplicación experimenta picos de tráfico que abruman la base de datos
- Las operaciones de lectura superan significativamente las operaciones de escritura
La infraestructura modular de Adalo maneja el almacenamiento en caché a nivel de plataforma, lo que significa que las aplicaciones construidas en la plataforma se benefician de la recuperación de datos optimizada sin configuración manual de caché. El sistema procesa 20 millones+ de solicitudes de datos diarios con una disponibilidad del 99%+, demostrando la efectividad de sus optimizaciones de rendimiento integradas.
4. Particionar conjuntos de datos grandes
Cuando las tablas crecen hasta millones de filas, incluso las consultas mejor indexadas pueden comenzar a ralentizarse. Particionamiento ofrece una forma de abordar esto dividiendo tablas grandes en piezas más pequeñas y manejables—llamadas particiones—mientras se las trata como una única tabla lógica. Esto permite que el motor de base de datos utilice eliminación de particiones, que omite particiones irrelevantes durante una consulta, reduciendo significativamente la cantidad de datos que necesita escanear. La clave es elegir el método correcto para dividir sus datos para garantizar un escaneo eficiente.
Particionamiento Horizontal vs. Vertical
Hay dos formas principales de particionar datos: particionamiento horizontal y particionamiento vertical.
- Particionamiento horizontal divide la tabla por filas, a menudo basándose en una columna específica como una fecha o región. Por ejemplo, podría dividir una tabla de ventas en fragmentos mensuales. Este método funciona particularmente bien para datos de series temporales o escenarios donde las consultas frecuentemente filtran por un rango específico.
- Particionamiento vertical, por otro lado, separa columnas. Es ideal para tablas amplias con muchos campos, especialmente si solo se accede regularmente a algunos campos. Por ejemplo, podría descargar BLOBs grandes o campos rara vez utilizados en tablas separadas.
Aquí hay un ejemplo del mundo real: particionar una tabla de pedidos de 5.000.000 de filas de Airtable por mes redujo el tiempo de consulta de 23ms a solo 1ms. Los motores de base de datos modernos como SQL Server pueden manejar hasta 15.000 particiones por tabla. Sin embargo, es importante no exagerar—el sobre-particionamiento puede llevar a un mayor uso de memoria y afectar el rendimiento si las consultas terminan escaneando múltiples particiones.
| Tipo de Particionamiento | Método | Mejor para |
|---|---|---|
| Horizontal | Divide filas (por ejemplo, por rango de fecha o ID) | Grandes conjuntos de datos con consultas basadas en rango |
| Vertical | Divide columnas (por ejemplo, separando BLOBs de campos frecuentemente accedidos) | Tablas amplias donde solo algunos campos se consultan regularmente |
Eligiendo la Clave de Partición Correcta
Para que el particionamiento funcione efectivamente, elija una columna que se use frecuentemente en cláusulas WHERE. Esto garantiza que la base de datos pueda aprovechar plenamente la eliminación de particiones. Además, alinee sus índices con el esquema de particionamiento para mejorar las tareas de mantenimiento. El particionamiento es especialmente adecuado para cargas de trabajo OLAP que implican escaneos grandes, en lugar de sistemas OLTP donde las consultas generalmente recuperan filas individuales.
Para constructores de aplicaciones que trabajan con grandes conjuntos de datos, la infraestructura de Adalo ahora se escala con las necesidades de la aplicación—no hay límite superior en registros de base de datos para planes pagos. Con las configuraciones de relaciones de datos correctas, las aplicaciones construidas en la plataforma pueden escalar más allá de 1 millón de usuarios activos mensuales. Esto elimina la necesidad de estrategias de particionamiento manual que otras plataformas con límites de registros requieren.
5. Revisar Planes de Ejecución de Consultas
Una vez que ha abordado la indexación y la refactorización de consultas, profundizar en planes de ejecución puede proporcionar información más profunda sobre el rendimiento de las consultas. Incluso las consultas bien optimizadas podrían encontrar cuellos de botella inesperados, y los planes de ejecución ayudan a descubrir cómo la base de datos procesa una consulta. Detallan cosas como uso de índices, métodos de unión y operaciones de ordenamiento.
Usando EXPLAIN y Herramientas de Plan de Ejecución
En PostgreSQL, herramientas como EXPLAIN y EXPLAIN ANALYZE son invaluables. EXPLAIN proporciona costos estimados, mientras que EXPLAIN ANALYZE agrega métricas de rendimiento reales, como recuentos de filas y tiempos de ejecución. Al comparar estos, puede detectar discrepancias que podrían apuntar a estadísticas desactualizadas o indexación subóptima. De manera similar, los planes de ejecución reales de SQL Server en Management Studio ofrecen información comparable. Estas herramientas ayudan a identificar ineficiencias que podrían no ser obvias a través de otras técnicas de optimización.
Qué Buscar
Al analizar un plan de ejecución, preste atención a patrones como "Escaneo Secuencial" en tablas grandes. Esto a menudo sugiere que agregar un índice podría mejorar el rendimiento. Además, busque condiciones de filtro que descarten la mayoría de las filas después de escanear, ya que estas podrían beneficiarse de convertirse en una operación de "Condición de Índice". Otra bandera roja son operaciones de ordenamiento o hash que se derraman en disco, lo que puede aumentar significativamente la latencia de las consultas. Comparar el tiempo de CPU con el tiempo transcurrido también puede revelar si su consulta está limitada por el uso de CPU o esperando operaciones de E/S.
Si un único operador, como "Ordenamiento" o "Combinación Hash", representa el 90% del costo de la consulta, es un objetivo claro para la optimización. También puede experimentar deshabilitando temporalmente ciertas opciones del planificador para probar estrategias de combinación alternativas y ver si funcionan mejor en la práctica. Esté atento a advertencias sobre conversiones de tipos de datos implícitas, ya que estas pueden obligar al motor a procesar cada fila individualmente, socavando la eficiencia del índice.
Análisis de Rendimiento Automatizado
Para aquellos que prefieren no analizar manualmente los planes de ejecución, Adalo ofrece X-Ray—una función de IA que identifica problemas de rendimiento antes de que afecten a los usuarios. Este enfoque proactivo del monitoreo de rendimiento significa que puede detectar y corregir cuellos de botella sin profundizar en los internos de la base de datos. La función destaca posibles preocupaciones de escalabilidad y sugiere optimizaciones, lo que la hace particularmente valiosa para constructores no técnicos que escalan sus aplicaciones.
Comparación de Enfoques de Base de Datos para Constructores de Aplicaciones
Al elegir una plataforma de construcción de aplicaciones, el rendimiento y la escalabilidad de la base de datos deben ser consideraciones principales. Diferentes plataformas manejan el almacenamiento de datos y la optimización de consultas de formas fundamentalmente diferentes.
| Plataforma | Enfoque de Base de Datos | Límites de registros | Precio inicial |
|---|---|---|---|
| Adalo | Incorporado + conexiones externas | Ilimitado en planes pagos | $36/mes |
| Bubble | Incorporado con Unidades de Carga de Trabajo | Limitado por cálculos de carga de trabajo | $69/mes |
| Glide | Basado en hojas de cálculo | Limitado, se aplican cargos adicionales | $60/mes |
| FlutterFlow | Solo externo (administrado por el usuario) | Depende del proveedor externo | $70/mes + costos de base de datos |
Bubble ofrece más opciones de personalización, pero esa flexibilidad a menudo resulta en aplicaciones más lentas que sufren bajo una carga aumentada. Muchos usuarios de Bubble terminan contratando expertos para optimizar sus aplicaciones—las afirmaciones de millones de MAU típicamente solo son alcanzables con ayuda profesional. La solución de aplicación móvil de Bubble también es un envoltorio de la aplicación web, introduciendo desafíos potenciales a escala.
FlutterFlow es técnicamente "low-code" en lugar de "no-code" y se dirige a usuarios técnicos. Los usuarios deben configurar y administrar su propia base de datos externa, lo que requiere una complejidad de aprendizaje significativa. Cualquier configuración menos que óptima puede crear problemas de escala, por lo que el ecosistema de FlutterFlow es rico en expertos pagados.
Glide destaca en aplicaciones basadas en hojas de cálculo pero crea aplicaciones genéricas y simplistas con libertad creativa limitada. No admite la publicación en App Store de Apple o Google Play Store, limitando las opciones de distribución.
Conclusión
Reducir la latencia de consultas de base de datos se trata de mejorar la velocidad y garantizar la escalabilidad. Técnicas como indexación, escritura de consultas eficientes, almacenamiento en caché, particionamiento y revisión de planes de ejecución pueden convertir consultas lentas de 30 segundos en respuestas ultrarrápidas, subsegundos.
Pero los beneficios van más allá de solo la velocidad. Las consultas simplificadas significan que se consumen menos recursos del servidor, lo que puede reducir los costos mensuales y garantizar una experiencia más suave a medida que crece su base de usuarios. Las consultas eficientes también ayudan a reducir la tensión del servidor y evitar alcanzar límites de velocidad de API, como Airtablela restricción de 5 solicitudes por segundo. Los pequeños ajustes ahora pueden ahorrarte grandes dolores de cabeza en el futuro.
Adalo, un constructor de aplicaciones impulsado por IA, simplifica estas optimizaciones a través de su interfaz visual y backend integrado. Para aplicaciones con conjuntos de datos más pequeños, la base de datos integrada de Adalo ofrece latencia cero de API con rendimiento rápido. ¿Necesita escalar o trabajar colaborativamente? Puede conectarse a bases de datos externas como Airtable, PostgreSQL o MS SQL Server usando External Collections, disponible en el plan Professional a partir de $36 por mes. Esta flexibilidad le permite comenzar con una configuración simple y escalar según sea necesario sin renovar su aplicación.
Para comenzar, enfóquese en perfilar sus consultas más lentas con herramientas como EXPLAIN y aborde primero los cuellos de botella más apremiantes. Ya sea agregando un índice o configurando una capa de almacenamiento en caché, cada mejora se basa en la anterior. Como señala sabiamente Mike Payne de Paessler :
No puedes optimizar lo que no puedes ver. El monitoreo de base de datos ilumina exactamente dónde residen los problemas de rendimiento.
Una vez que haya identificado los puntos problemáticos, las soluciones a menudo son sencillas y ofrecen resultados inmediatos.
Publicaciones de Blog Relacionadas
- 8 formas de optimizar el rendimiento de tu aplicación sin código
- Cómo crear una aplicación usando datos de IBM DB2
- 5 métricas para rastrear el rendimiento de aplicaciones sin código
- Escalado de aplicaciones sin código para grandes conjuntos de datos
Preguntas frecuentes
¿Por qué elegir Adalo sobre otras soluciones de construcción de aplicaciones?
Adalo es un constructor de aplicaciones impulsado por IA que crea verdaderas aplicaciones iOS y Android nativas. A diferencia de los envoltorios web, se compila a código nativo y se publica directamente en la App Store de Apple y Google Play Store desde una única base de código—la parte más difícil de lanzar una aplicación se maneja automáticamente.
¿Cuál es la forma más rápida de construir y publicar una aplicación en la App Store?
La interfaz de arrastrar y soltar de Adalo combinada con la construcción asistida por IA a través de Magic Start y Magic Add le permite crear aplicaciones completas en horas en lugar de semanas. La plataforma maneja todo el proceso de envío de App Store, eliminando las barreras técnicas que típicamente ralentizan los lanzamientos de aplicaciones.
¿Puedo optimizar fácilmente las consultas de base de datos en mi aplicación?
Sí, con la interfaz visual de Adalo y el backend integrado, puede optimizar el rendimiento de la base de datos sin escribir SQL. Para aplicaciones con conjuntos de datos más pequeños, la base de datos integrada de Adalo ofrece latencia cero de API, y puede conectarse a bases de datos externas como PostgreSQL o Airtable para conjuntos de datos más grandes usando External Collections.
¿Cuál es la forma más impactante de reducir la latencia de consultas de base de datos?
La indexación adecuada de la base de datos a menudo es el primer paso más impactante, ya que los índices actúan como atajos que apuntan directamente a las filas necesarias en lugar de escanear tablas completas. Enfóquese en indexar columnas comúnmente utilizadas en cláusulas WHERE, JOIN y ORDER BY para obtener las mejores ganancias de rendimiento.
¿Cuándo debo usar almacenamiento en caché versus particionamiento para conjuntos de datos grandes?
Use almacenamiento en caché cuando tenga datos a los que se accede frecuentemente que no cambian a menudo—herramientas como Redis o Memcached pueden manejar cientos de miles de solicitudes por segundo. Use particionamiento cuando sus tablas crezcan a millones de filas y las consultas filtren por rangos específicos como fechas, ya que permite que la base de datos omita datos irrelevantes completamente.
¿Cómo identifico qué consultas están causando problemas de rendimiento?
Use herramientas de plan de ejecución de consultas como EXPLAIN en PostgreSQL o planes de ejecución reales en SQL Server para ver exactamente cómo la base de datos procesa sus consultas. Adalo también ofrece X-Ray, una característica de IA que identifica problemas de rendimiento antes de que afecten a los usuarios.
¿Por qué debo evitar usar SELECT * en mis consultas de base de datos?
Usar SELECT * recupera todas las columnas de una tabla, desperdiciando memoria y ancho de banda cuando solo necesita campos específicos. Especificar solo las columnas que necesita puede reducir significativamente el tiempo de ejecución y el uso de memoria—los puntos de referencia muestran que cambiar a consultas dirigidas puede reducir el consumo de memoria casi un 40%.
¿Cuál es más asequible, Adalo o Bubble?
Adalo comienza en $36/mes con uso ilimitado y sin límites de registros en planes pagos. Bubble comienza en $69/mes con cargos de Workload Unit basados en el uso y límites de registros. Adalo también incluye actualizaciones de aplicaciones ilimitadas una vez publicadas, mientras que Bubble tiene restricciones de republicación.
¿Es Adalo mejor que FlutterFlow para aplicaciones móviles?
Para usuarios no técnicos, sí. FlutterFlow es "low-code" dirigido a usuarios técnicos que deben configurar y administrar su propia base de datos externa. Adalo incluye una base de datos integrada sin límites de registros en planes pagos, y su constructor visual se describe como "tan fácil como PowerPoint" mientras sigue produciendo aplicaciones nativas para iOS y Android.
¿Tiene Adalo límites de registros de base de datos?
No. Los planes pagos tienen registros de base de datos ilimitados sin límites. Con las configuraciones correctas de relaciones de datos, las aplicaciones de Adalo pueden escalar más allá de 1 millón de usuarios activos mensuales. La infraestructura modular de la plataforma escala automáticamente con las necesidades de su aplicación.
Construye tu aplicación rápidamente con una de nuestras plantillas de aplicación prediseñadas
Comienza a construir sin códigoContenido Relacionado

Mejora del Tiempo de Respuesta de API con Bases de Datos Heredadas
Acelere las API usando bases de datos heredadas con ajuste de consultas, indexación, almacenamiento en caché, agrupación de conexiones y correcciones de consultas N+1 para reducir la latencia

Resolución de Problemas de Rendimiento en APIs Heredadas
Reduce la latencia de la API heredada con almacenamiento en caché, ajuste de consultas, envolturas de API y migración gradual de microservicios — ganancias rápidas prácticas y soluciones a largo plazo

Cómo la IA y las MicroAplicaciones Están Preparadas para Cambiar el Flujo de Trabajo Corporativo
Las microaplicaciones impulsadas por IA automatizan tareas repetitivas, modernizan sistemas heredados y permiten crear aplicaciones sin código para acelerar flujos de trabajo, reducir costos y

Futuro de SaaS: Automatización de Flujos de Trabajo Impulsada por IA
Cómo el SaaS impulsado por IA utiliza agentes autónomos, flujos de trabajo en lenguaje natural y optimización predictiva para acelerar procesos, reducir costos e integrar